In this notebook, we are going to use autoencoder architecture in Pytorch to reduce feature dimensions and visualiations.
First, to install PyTorch, you may use the following pip command,
$ pip install torch torchvision |
The torchvision package contains the image data sets that are ready for use in PyTorch.
More details on its installation through this guide from pytorch.org.
Setup
importing relevant dependencies.
import matplotlib.pyplot as plt |
Set seed and other configurations for reproducibility.
seed = 21 |
Set the batch size, the number of training epochs, and the learning rate.
batch_size = 512 |
Dataset
load the MNIST dataset as a convienient exampe using the torchvision package.
transform = torchvision.transforms.Compose([torchvision.transforms.ToTensor()]) |
check one example data
examples = enumerate(train_loader) |
example_data[0][0].max() |
tensor(1.)
Autoencoder
An autoencoder is a type of neural network that finds the function mapping the features x to itself. This objective is known as reconstruction, and an autoencoder accomplishes this through the following process:
(1) an encoder learns the data representation in lower-dimension space,
(2) a decoder learns to reconstruct the original data based on the learned representation by the encoder.
In the following we define our autoencoder class with fully connected layers and activation functions for both its encoder and decoder components.
from torch import Tensor |
Before using our defined autoencoder class, we have the following things to do:
1. We configure which device we want to run on.
2. We instantiate an AE object.
3. We define our optimizer.
4. We define our reconstruction loss.
# use gpu if available |
We train our autoencoder for our specified number of epochs.
for epoch in range(epochs): |
epoch : 1/50, recon loss = 0.07389576
epoch : 2/50, recon loss = 0.05296296
epoch : 3/50, recon loss = 0.04810659
epoch : 4/50, recon loss = 0.04541392
epoch : 5/50, recon loss = 0.04336656
epoch : 6/50, recon loss = 0.04195889
epoch : 7/50, recon loss = 0.04092639
epoch : 8/50, recon loss = 0.04033839
epoch : 9/50, recon loss = 0.03984492
epoch : 10/50, recon loss = 0.03948938
epoch : 11/50, recon loss = 0.03939159
epoch : 12/50, recon loss = 0.03877884
epoch : 13/50, recon loss = 0.03859487
epoch : 14/50, recon loss = 0.03825530
epoch : 15/50, recon loss = 0.03797148
epoch : 16/50, recon loss = 0.03789599
epoch : 17/50, recon loss = 0.03754379
epoch : 18/50, recon loss = 0.03740290
epoch : 19/50, recon loss = 0.03735819
epoch : 20/50, recon loss = 0.03729593
epoch : 21/50, recon loss = 0.03699356
epoch : 22/50, recon loss = 0.03768872
epoch : 23/50, recon loss = 0.03694447
epoch : 24/50, recon loss = 0.03680794
epoch : 25/50, recon loss = 0.03654349
epoch : 26/50, recon loss = 0.03630730
epoch : 27/50, recon loss = 0.03620429
epoch : 28/50, recon loss = 0.03615394
epoch : 29/50, recon loss = 0.03615029
epoch : 30/50, recon loss = 0.03593704
epoch : 31/50, recon loss = 0.03589566
epoch : 32/50, recon loss = 0.03570651
epoch : 33/50, recon loss = 0.03599412
epoch : 34/50, recon loss = 0.03587519
epoch : 35/50, recon loss = 0.03641265
epoch : 36/50, recon loss = 0.03615064
epoch : 37/50, recon loss = 0.03541873
epoch : 38/50, recon loss = 0.03545310
epoch : 39/50, recon loss = 0.03534035
epoch : 40/50, recon loss = 0.03541123
epoch : 41/50, recon loss = 0.03511182
epoch : 42/50, recon loss = 0.03499481
epoch : 43/50, recon loss = 0.03487989
epoch : 44/50, recon loss = 0.03506399
epoch : 45/50, recon loss = 0.03487079
epoch : 46/50, recon loss = 0.03481269
epoch : 47/50, recon loss = 0.03454635
epoch : 48/50, recon loss = 0.03444027
epoch : 49/50, recon loss = 0.03448961
epoch : 50/50, recon loss = 0.03482613
Let’s extract some test examples to reconstruct using our trained autoencoder.
test_dataset = torchvision.datasets.MNIST( |
Visualize Reconstruction Quality
Let’s try to reconstruct some test images using our trained autoencoder.
with torch.no_grad(): |
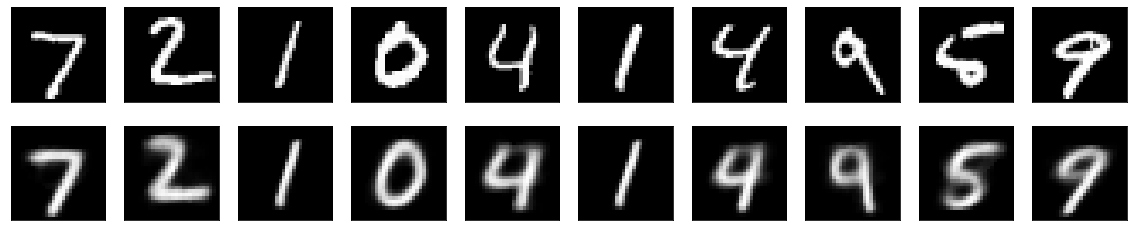
Analysis so far
as we can see the reconstruciton is good, but not super great; this is mainly because we use only 2 nodes for the
middle hidden layer. Using only 2 nodes is easy for us to see the reduced dimensions, but probably not good enough
to capture all the sailent features. For pure feature reduction purpose, we can choose a bigger number of nodes
for the middel hidden layer.
Visualize the middel hidden layer with 2 nodes for lower dimension reduction
# reduce dimension example |
import numpy as np |
array([[-0.43485078, 0.31671965],
[ 1.5935664 , 4.4088674 ],
[ 9.075943 , 4.4781566 ],
...,
[-0.90027434, 0.3994102 ],
[-2.9567816 , 2.2586362 ],
[-4.884531 , 1.9589175 ]], dtype=float32)
labels = test_dataset.targets.numpy() |
import pandas as pd |
<AxesSubplot:xlabel='x', ylabel='y'>


