Previously, we have discussed how to implement a real time semantic search using sentence transformer and FAISS.
real time semantic search
Here, we talk more about indexing in FAISS.
The most popular indexes we should look at are the simplest — flat indexes.
Flat indexes are ‘flat’ because we do not modify the vectors that we feed into them.
Because there is no approximation or clustering of our vectors — these indexes produce the most accurate results. While we have perfect search quality, this comes at the cost of significant search times.
Two flat indexes
Two common flat index:
- IndexFlatL2, which uses Euclidean/L2 distance
- IndexFlatIP, which uses inner product distance (similar as cosine distance but without normalization)
The search speed between these two flat indexes are very similar, and IndexFlatIP is slightly faster for larger datasets.
See the following query time vs dataset size comparison: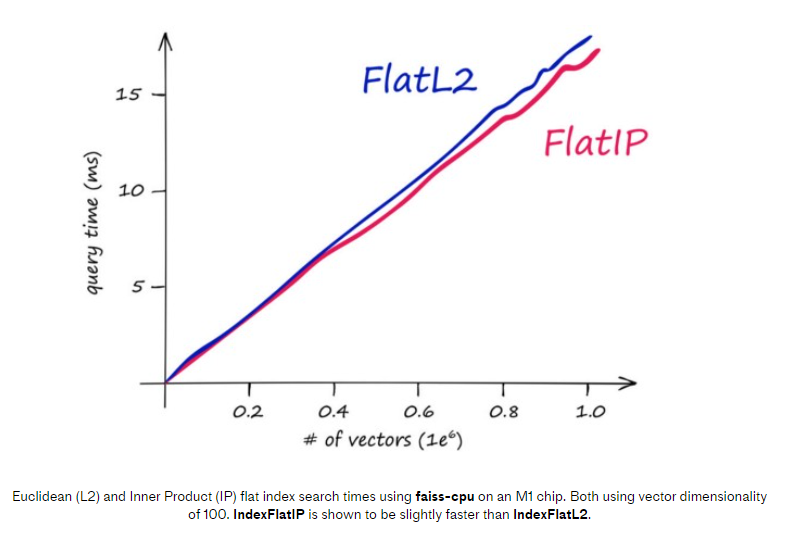
how to normalize similarity metrics
If the vectors we indexed are not normalized, the similarity metrics came out from FAISS are not normalized either.
For example, sometimes we want to have a cosine similarity metrics, where we can have a more meaningful threshold to compare.
It’s very easy to do it with FAISS, just need to make sure vectors are normalized before indexing, and before sending the query vector.
Example code, during indexing time:
index = faiss.IndexIDMap(faiss.IndexFlatIP(768)) |
during query time:
query_vector = model.encode([query])
k = 3
faiss.normalize_L2(query_vector)
top_k = index.search(query_vector, k)

