There are situations where we need to run multiple notebooks or algorithms that are closely related. In this case, it makes sense to log all the information into one central place.
We can leverage MLflow with Databricks to achieve this goal.
First, let’s see what information we can log with MLflow?
Information to log in MLflow
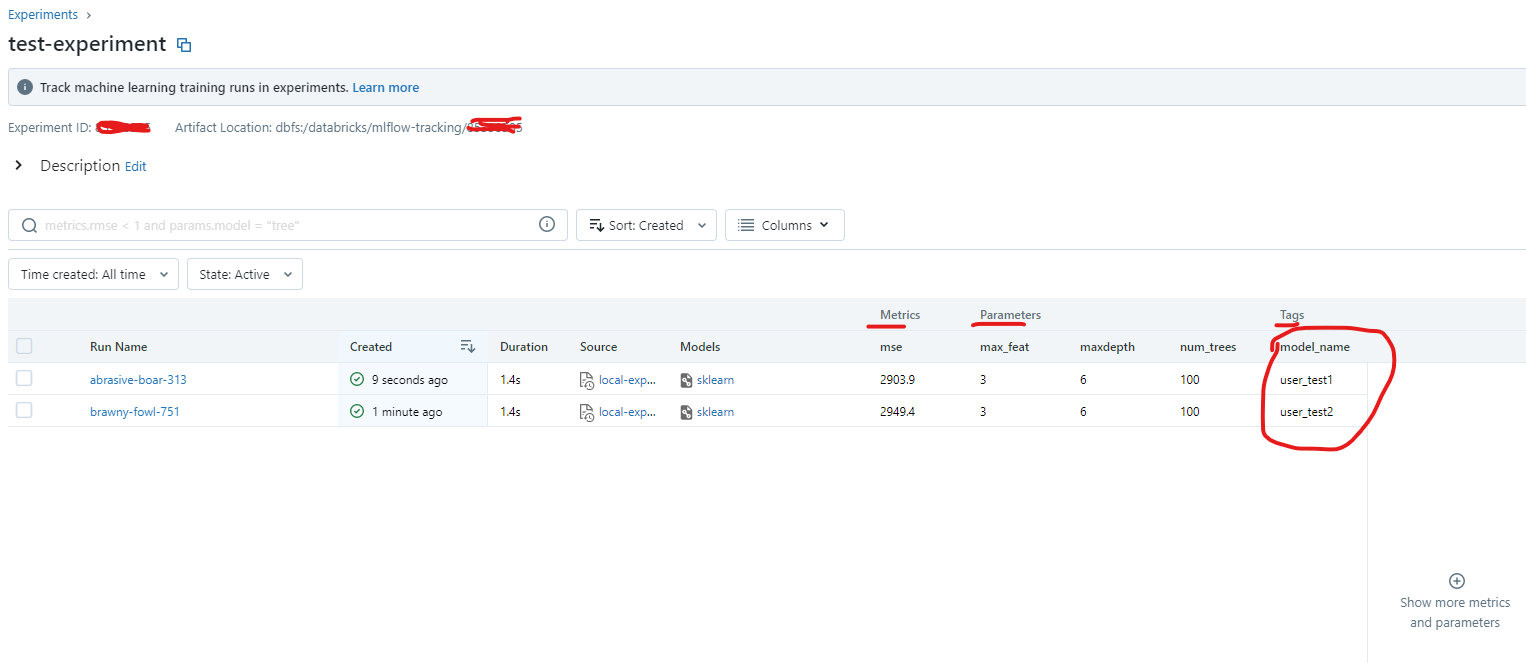
mlflow.log_param() logs a single key-value param in the currently active run. The key and value are both strings. Use mlflow.log_params() to log multiple params at once.
mlflow.log_metric() logs a single key-value metric. The value must always be a number. MLflow remembers the history of values for each metric. Use mlflow.log_metrics() to log multiple metrics at once.
mlflow.set_tag() sets a single key-value tag in the currently active run. The key and value are both strings. Use mlflow.set_tags() to set multiple tags at once.
mlflow.log_artifact() logs a local file or directory as an artifact, optionally taking an artifact_path to place it in within the run’s artifact URI. Run artifacts can be organized into directories, so you can place the artifact in a directory this way.
mlflow.log_artifacts() logs all the files in a given directory as artifacts, again taking an optional artifact_path.
To distinguish different algorithm names, we can use the mlflow.set_tag()function to log the algorithm name into the experiments.
Example code to use in Databricks notebooks
import mlflow import mlflow.sklearn from sklearn.ensemble import RandomForestRegressor from sklearn.metrics import mean_squared_error
# Import the dataset from scikit-learn and create the training and test datasets. from sklearn.model_selection import train_test_split from sklearn.datasets import load_diabetes
db = load_diabetes() X = db.data y = db.target X_train, X_test, y_train, y_test = train_test_split(X, y)
# This run uses mlflow.set_experiment() to specify an experiment in the workspace where runs should be logged. # If the experiment specified by experiment_name does not exist in the workspace, MLflow creates it. # Access these runs using the experiment name in the workspace file tree.
experiment_name = "/xxxx/test-experiment" # pluging your path at Databricks, where the "test-experiment" is the actual experiment name mlflow.set_experiment(experiment_name)
Reprint policy:
All articles in this blog are used except for special statements
CC BY 4.0
reprint policy. If reproduced, please indicate source
robot learner
!